Research Statement
A highly opinionated response to why I do research
« Home
Summary. We live in the Information Age. Innovations in information technology, such as the World Wide Web (a.k.a. the Web), play a pivotal role in advancing today's knowledge-based societies and should be protected at all costs. My research revolves around the security and privacy of the Web, with an emphasis on problems that impact the way we adopt and use its underlying technologies. My ultimate goal is to empower Web users by building software systems that are resilient to centralized control, give users full control of their data, and offer higher levels of privacy and security.
One characteristic of the Information Age is that our society is surrounded by a high-tech global economy in which wealth is knowledge and growth is learning. This system of the world leads to a fundamental question about our experience with the Web: When we go online, how do we identify ourselves, connect with others, and gain knowledge?
When I started exploring this question in 2010, as part of an early investigation of Web single sign-on [1], the answer was predominantly "Facebook." True then as it is now, we live in the Facebook Age. We identify ourselves with our Facebook accounts, we connect with others by sending friend requests, and we learn about the world from our newsfeeds. For many, the Web has become Facebook; or Google, Twitter, and the like. Regardless of which “walled garden” we choose to visit, the Web is far distant from its open standard origin. Today’s Web is dominated by a few large websites that use closed, centralized systems. Moreover, most of these websites implement a business model that allows them to be used for free in exchange for user data, which is then used for highly-targeted advertising. Other than treating users as commodities, this “free-to-use” business model is fundamentally flawed. A price of zero greatly reduces liabilities to users, especially privacy and security, incentivizes the use of abusive retention strategies, which profile users and herd them towards sharing more data, and prohibits market learning by hiding pricing signals, which hinders competition and innovation. Yet, the Web seems to work well in practice, does it not? Starting early 2011, I set out to test this proposition, focusing on the privacy and security implications of using large, centralized websites like Facebook.
As Facebook had 500 million monthly active users in 2011, and projecting its first billion within a year, I decided to investigate how feasible it is for an attacker to achieve a seemingly far-fetched goal: To automate, and effectively fake, the whole Facebook experience for many adversarial objectives, such as private data collections and misinformation.
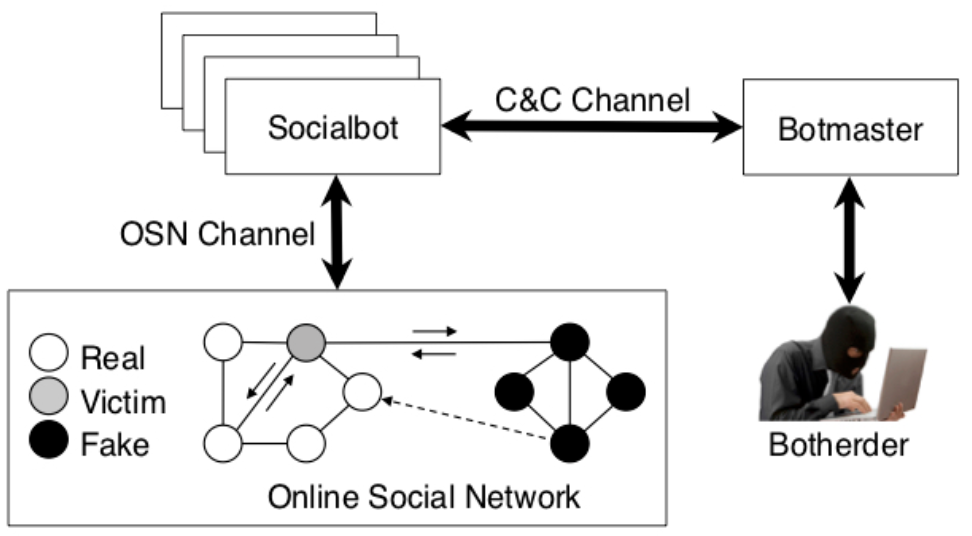
Figure 1. Social botnet
After presenting the case for this investigation to The Office of the Privacy Commissioner of Canada, I started designing a Web automation tool called a socialbot. In concept, a socialbot controls a fictitious Facebook account and can perform social activities similar to those of real users, such as sending friend requests and posting messages. As such, a socialbot is designed to deceive and pass itself off as a human being. A network of socialbots can be controlled by an adversary in a command-and-control fashion, similar to malware botnets. For a social botnet to operate at scale, all aspects of its operation must be automated, including account creation, profile setup, befriending, and posting messages. The main challenge is not automation per se, but being able to infiltrate and connect with the rest of the Facebook network. This is the case because successful social infiltration is essential for evaluating privacy and security concerns, as isolated socialbots pose minimal risk to users and are easy to detect. To overcome this challenge, the socialbots are designed to exploit known concepts in sociology, such as targeting users with whom they have mutual friends (i.e., triadic closure), in order to improve their infiltration success rate.
After consulting with the university’s research ethics board, I carefully operated a network of 100 socialbots on Facebook for eight weeks, resulting in one main finding: With up to 80% infiltration rate, 250GB of raw data collected from more than one million users, and less than 20% detection rate, Facebook and its users are left defenseless [2,3]. This was the first comprehensive study that showed the vulnerability of large, centralized online social networks (OSNs) like Facebook to fake, abusive automation, and has received the outstanding paper award at ACSAC '11. It also resulted in a private presentation to the InfoSec Technology Transition Council for the Science & Technology Directorate at the U.S. Department of Homeland Security, in addition to an international news coverage, years before Facebook was formally questioned by the U.S. Senate about its handling of user data, fake news, and political bias in 2018.
In 2012, shortly after this investigation, I started looking at how OSNs can protect their users from automated fake accounts [4]. Being closed and centralized, it is not possible to evaluate new defenses against the ones deployed by OSNs in practice, unless researchers find a way to collaborate with these OSNs. Back then, there were two main approaches to detect fake accounts. The first is statistical and relies on detecting anomalies in user behavior using machine learning. The second is mathematical and relies on computing properties of the social graph, which represents users and their friendships, using combinatorics and probability theory. In 2013, I showed that both approaches are ineffective against socialbots, as their threat model assumes fake accounts that cannot behave like real users; they must be spammy and relatively isolated from real accounts [5]. This investigation resulted in the best paper award at ASONAM '13, and highlighted the challenge for designing defense systems that consider a more realistic and resourceful adversary who can operate a social botnet.
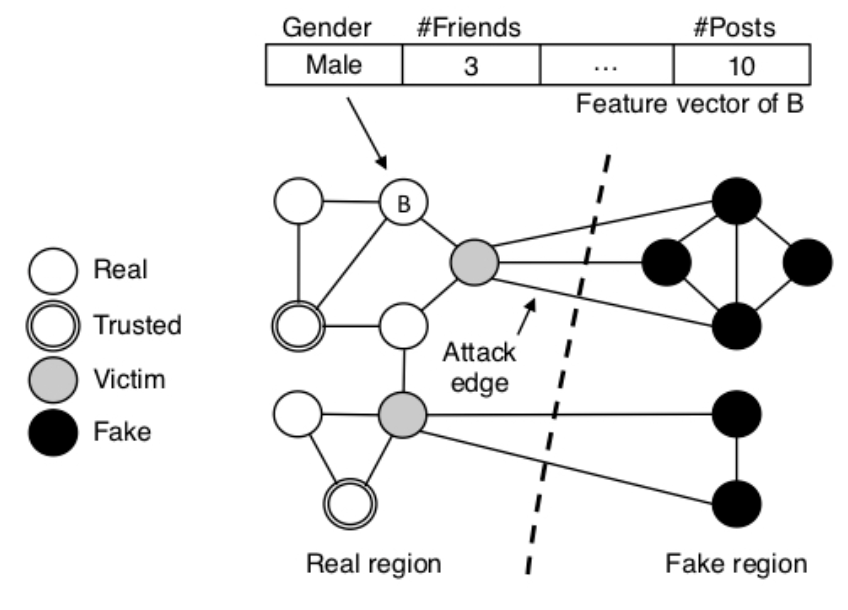
Figure 2. Integro's high-level design
From 2014 to 2015, after studying the human factors affecting social infiltration [6], I worked on building and improving Integro: A defense system that combines both approaches in a novel, infiltration-resilient user ranking scheme that helps OSNs detect fake accounts [7,8]. Integro predicts victims of fake accounts (i.e., potential victims) using supervised machine learning, with features extracted from basic account information. As such, it makes no limiting assumptions about fakes and shifts the focus to real accounts. Integro weights the social graph such that edges incident to potential victims have lower weights than others. It then computes a rank for each account based on the landing probability of a short, modified random walk that starts from a known real account. This walk is biased towards traversing accounts that are reachable through edges with higher weights, which means it is highly unlikely to land on fake accounts and most real accounts will be ranked higher than fake accounts, even if fakes have infiltrated many real accounts.
I implemented Integro on top of open-source distributed systems and deployed it at Tuenti, a progressive OSN with millions of users. A production-class evaluation resulted in detecting nearly 10 times more fake accounts than existing defense systems. This was done in under 30 minutes for a social graph with 160 million nodes on 33 commodity machines.
It is important to highlight that websites should take the initiative and integrate, or at least evaluate, new defense systems against theirs, hopefully before innovation is stifled by new, restrictive Web regulations that are drafted in response to emerging security and privacy concerns. This rings true with the new EU GDPR law put in place and the recent push in the U.S. to regulate high-tech companies.
In 2016, I started exploring how victim prediction can be applied to different Web security problems [9]. I quickly realized, however, that this approach gives more legitimacy to collecting user data by closed, centralized systems. Moreover, operating “big data silos” will eventually be infeasible, as there will be far more data than a single, centralized system can manage for free.
With this perspective in mind, I revisited the threat of social botnets as an instance of the Sybil attack, which is a well-studied problem in distributed, decentralized identity-based system, such as Peer-to-Peer (P2P) networks. In the Sybil attack, an adversary abuses the system by forging multiple, dishonest identities, each called a Sybil, and joins the system under these identities for malicious objectives. A decentralized, distributed system that is resilient to the Sybil attack is a good candidate for influencing the design of next-generation Web systems. This is when I shifted my focus to Bitcoin and its underlying blockchain technology.
Bitcoin is a digital currency that uses a P2P network to move money from one user to another, each represented by a single node in the network, without the need for intermediaries, such as banks. Transactions are verified by loosely-organized nodes called miners and recorded in a public, distributed ledger called a blockchain. The security of the blockchain is established by a chain of cryptographic puzzles that miners compete to solve. Each miner that successfully solves a crypto puzzle is allowed to record a set of transactions, and to collect a reward in Bitcoins. The more mining power (i.e., resources) a miner applies, the better are its chances to solve the puzzle first. This reward structure, also called proof-of-work, provides an incentive for miners to contribute their resources to the system, and is essential to the currency’s decentralized nature.
The Bitcoin network relies on IP address-based identity. In order to defend against Sybil attackers who attempts to fill the network with dishonest nodes, an honest node only makes an outbound connection to one IP address per /16 subnet (i.e., one IP out of a block of 65 thousand IPs). This reduces the probability of an honest node connecting to peers that are dishonest all the time. To defend against a Sybil attacker who controls miners, consensus in Bitcoin requires the majority of miners in the network to agree on the state of the blockchain. As it is financially infeasible for an adversary to control the majority of the mining power in the network, the security of the blockchain is preserved. This new crypto economy defined by Bitcoin is novel, and is already fueling new blockchain-based Web systems, such as Filecoin for data storage and Steemit for social networking.
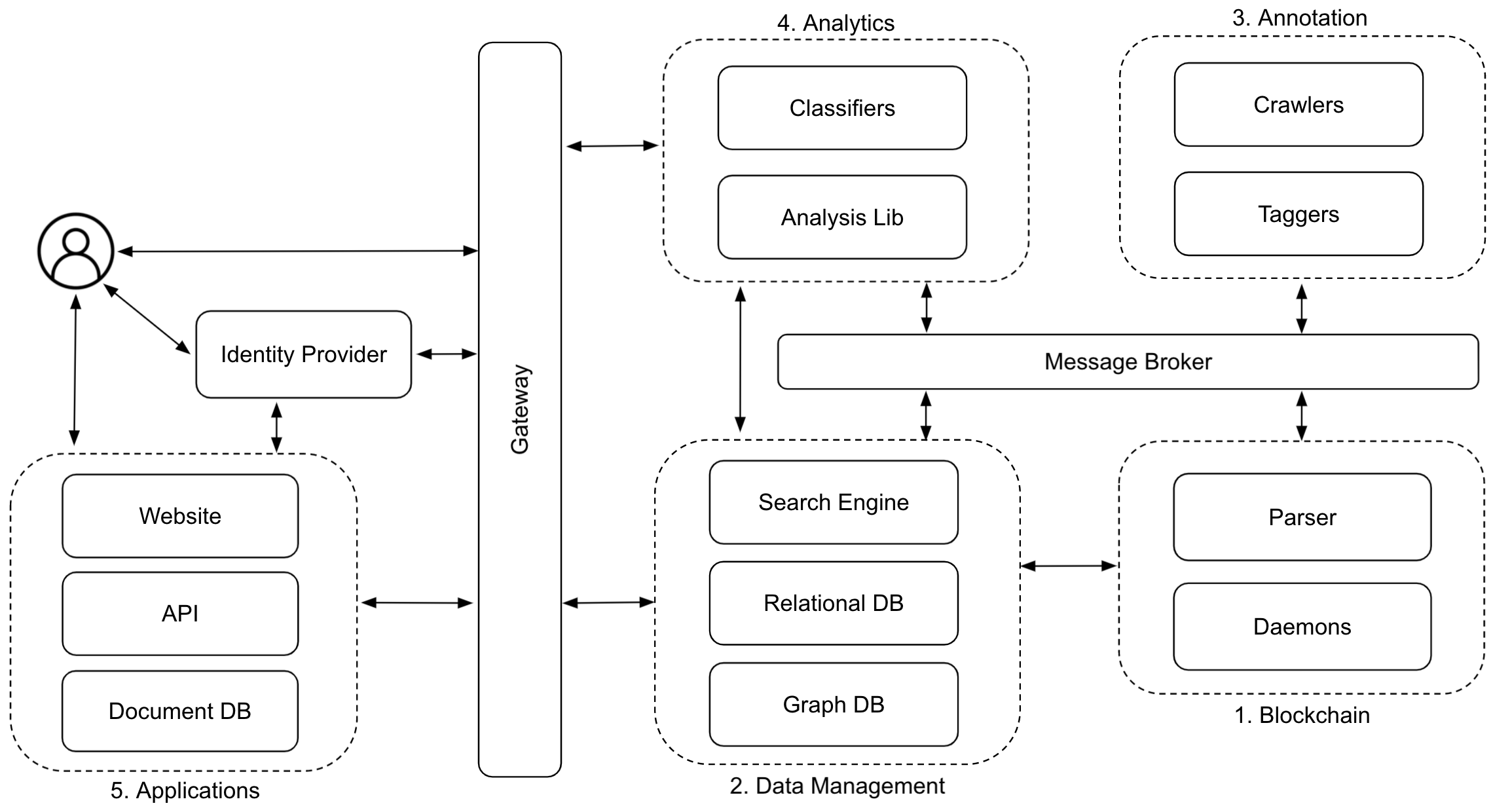
Figure 3. CIBR's high-level architecture
In 2017, to better understand how decentralized systems like Bitcoin affect the way we use the Web, I started a new focused effort called Cybersecurity Initiative for Blockchain Research (CIBR), and kicked off the research by looking at ways to link off-chain data (e.g., a Twitter account) to on-chain data (e.g., a Bitcoin address), focusing on applications related to privacy research and law enforcement. Existing blockchain analysis systems, such as BlockSci, focus on efficiently analyzing on-chain data, with no or limited support for auxiliary data. To address this limitation, I am currently building and improving CIBR-Lab: A full-stack search, tagging, classification, and analysis system for blockchains [10,11]. The challenge is to find a way to systematically incorporate auxiliary data into the blockchain so that a new class of queries, which involve clustering, linking, classifying, and searching on/off-chain data, can be performed using existing analysis systems. CIBR-Lab addresses this challenge by annotating on-chain data with tags, which are auxiliary, off-chain data crawled from the Web and other information networks, such as Tor. These tags are managed separately from the analysis sub-system as annotations, which can be clustered, linked, classified, and searched through blockchain transactions. To simplify blockchain analysis, CIBR-Lab separates functionality by defining a component-based, layered system architecture (i.e., a stack), where blockchain, data management, annotation, and analytics have separate component with well-defined and extendable interfaces between them. This allows CIBR-Lab to provide quick, partial answers to high-level queries like: "which Twitter accounts made Bitcoin payments to Silk Road."
As a proof of concept, we deployed CIBR-Lab in 2019 to investigate emerging security and privacy issues arising from analyzing off/on-chain data of popular technologies. In particular, we showed that one can deanonymize Tor hidden service users [12], uncover Ponzi schemes on Bitcoin [13], and identify users who made donations to open-source projects on GitHub[14]. My ongoing work with CIBR-Lab has led to a private presentation to The Office of Technology Research and Investigation at the U.S. Federal Trade Commission, multi-year, multi-million dollar research grants from Qatar National Research Fund, and an international news coverage.
For the short term, I plan to continue working on CIBR-Lab, focusing on fraud detection and transaction risk predictoin. I then plan to deploy CIBR-Lab as an interactive blockchain analytics service, with dashboards displaying real-time results of important, user-defined queries. Based on feedback from the U.S. Federal Trade Commission and Qatar Financial Center Regulatory Authority, such capabilities are extremely helpful to protect customers, comply with Know Your Customer and Anti-Money Laundering laws, and draft new, investor-friendly cryptocurrency regulations.
For the longer term, I plan to analyze the privacy and security of general-purpose, decentralized Internet platforms, such as Ethereum, EOS, and IPFS, which are currently used to build next-generation websites in the new Web, or Web 3.0. As users should have the freedom to choose where their data is stored and who is allowed to access it, I plan to focus on achieving true data ownership on the Web. One future direction is to decouple Web data from its applications, with mapping information residing on a public, permissioned blockchain. As such, a Web browser acts as a decentralized content explorer that executes user-defined, self-contained, tokenized applications. This also allows both versions of the Web to co-exist, with current centralized websites acting as both content and application providers.
-
San-Tsai Sun, Yazan Boshmaf, Kirstie Hawkey, and Konstantin BeznosovProc. of 2010 New Security Paradigms Workshop
NSPW ’10, Colonial Inn, Concord, MA, Dec 2010 -
Yazan Boshmaf, Ildar Muslukhov, Konstantin Beznosov, and Matei RipeanuProc. of 27th Annual Computer Security Applications Conference
ACSAC ’11, Orlando, FL, Dec 2011 — outstanding paper award -
Yazan Boshmaf, Ildar Muslukhov, Konstantin Beznosov, and Matei RipeanuElsevier Computer Networks
Volume 57 Issue 2, Pages 556-578, Feb 2013 -
Yazan Boshmaf, Ildar Muslukhov, Konstantin Beznosov, Matei RipeanuProc. of 5th USENIX Workshop on Large-Scale Exploits and Emergent Threats
LEET ’12, San Jose, CA, April 2012 -
Yazan Boshmaf, Konstantin Beznosov, and Matei RipeanuProc. of 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining
ASONAM ’13, Niagara Falls, Canada, August 2013 — best paper award -
Hootan Rashtian, Yazan Boshmaf, Pooya Jaferian, and Konstantin BeznosovProc. of 2014 Symposium on Usable Privacy and Security
SOUPS ’14, Menlo Park, CA, July 2014 -
Yazan Boshmaf, Dionysios Logothetis, Georgos Siganos, Jorge Lería, Jose Lorenzo, Matei Ripeanu, and Konstantin BeznosovProc. of 2015 Network and Distributed System Security Symposium
NDSS ’15, San Diego, CA, Feb 2015 -
Yazan Boshmaf, Matei Ripeanu, Konstantin Beznosov, and Elizeu Santos-NetoProc. 8th ACM Workshop on Artificial Intelligence and Security
AI-Sec ’15, Denver, CO, Oct 2015 -
Hassan Halawa, Konstantin Beznosov, Yazan Boshmaf, Baris Coskun, Elizeu Santos-Neto, and Matei RipeanuProc. of 2016 New Security Paradigms Workshop
NSPW ’16, C Lazy U Ranc, CO, Sep 2016 -
Yazan Boshmaf, Husam Al Jawaheri, and Mashael Al SabahProc. of 34th International Conference on ICT Systems Security and Privacy Protection
IFIP SEC ’19, Lisbon, Portugal, Jun 2019 -
Yazan Boshmaf, Isuranga Perera, Udesh Kumarasinghe, Sajitha Liyanage, and Husam Al JawaheriarXiv preprint
arXiv:2209.07202, Sep 2022 -
Husam Al Jawaheri, Mashael Al Sabah, Yazan Boshmaf, and Aiman ErbadElsevier Computers & Security
Volume 89, Article 101684, Feb 2020 -
Yazan Boshmaf, Charitha Elvitigala, Husam Al Jawaheri, Primal Wijesekera, and Mashael Al SabahProc. of 15th ACM Asia Conference on Computer and Communications Security
AsiaCCS ’20, Taipei, Taiwan, Oct 2020 -
Yury Zhauniarovich, Yazan Boshmaf, Husam Al Jawaheri, and Mashael Al SabaharXiv preprint
arXiv:1907.04002, Jul 2019